Avrorouter
Avrorouter
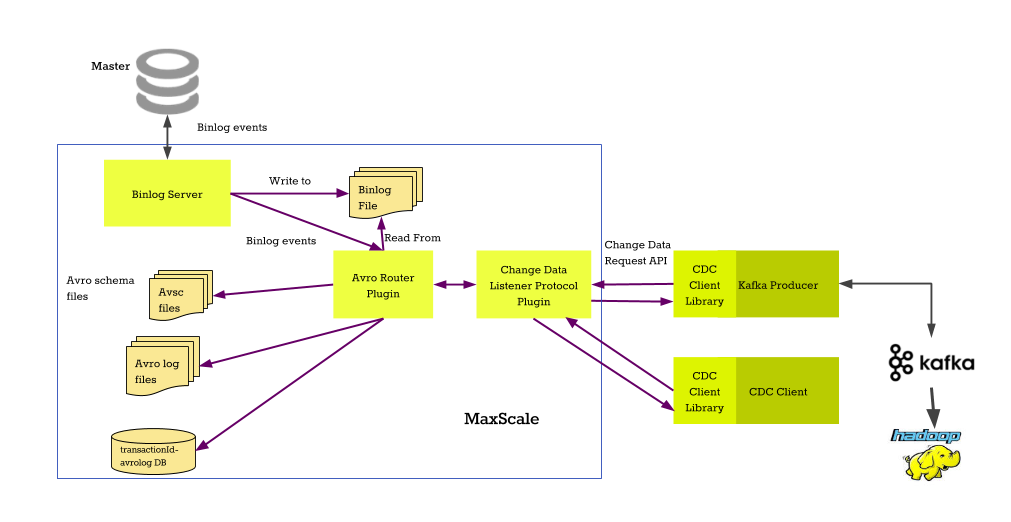
The avrorouter is a MariaDB 10.0 binary log to Avro file converter. It consumes binary logs from a local directory and transforms them into a set of Avro files. These files can then be queried by clients for various purposes.
This router is intended to be used in tandem with the Binlog Server. The Binlog Server can connect to a primary server and request binlog records. These records can then consumed by the avrorouter directly from the binlog cache of the Binlog Server. This allows MariaDB MaxScale to automatically transform binlog events on the primary to local Avro format files.
The avrorouter can also consume binary logs straight from the primary. This will remove the need to configure the Binlog Server but it will increase the disk space requirement on the primary server by at least a factor of two.
The converted Avro files can be requested with the CDC protocol. This protocol should be used to communicate with the avrorouter and currently it is the only supported protocol. The clients can request either Avro or JSON format data streams from a database table.
Direct Replication Mode
MaxScale 2.4.0 added a direct replication mode that connects the avrorouter directly to a MariaDB server. This mode is an improvement over the binlogrouter based replication as it provides a more space-efficient and faster conversion process. This is the recommended method of using the avrorouter as it is faster, more efficient and less prone to errors caused by missing DDL events.
To enable the direct replication mode, add either the servers or the cluster
parameter to the avrorouter service. The avrorouter will then use one of the
servers as the replication source.
Here is a minimal avrorouter direct replication configuration:
[maxscale] threads=auto [server1] type=server address=127.0.0.1 port=3306 [cdc-service] type=service router=avrorouter servers=server1 user=maxuser password=maxpwd [cdc-listener] type=listener service=cdc-service protocol=CDC port=4001
In direct replication mode, the avrorouter stores the latest replicated GTID in
the last_gtid.txt file located in the avrodir (defaults to
/var/lib/maxscale). To reset the replication process, stop MaxScale and remove
the file.
Additionally, the avrorouter will attempt to automatically create any missing schema files for tables that have data events for them but the DDL for those tables is not contained in the binlogs.
Configuration
For information about common service parameters, refer to the Configuration Guide.
Router Parameters
gtid_start_pos
- Type: string
- Mandatory: No
- Dynamic: No
- Default:
""
The GTID where avrorouter starts the replication from in direct replication mode. The parameter value must be in the MariaDB GTID format e.g. 0-1-123 where the first number is the replication domain, the second the server_id value of the server and the last is the GTID sequence number.
This parameter has no effect in the traditional mode. If this parameter is defined, the replication will start from the implicit GTID that the primary first serves.
server_id
- Type: number
- Mandatory: No
- Dynamic: No
- Default:
1234
The server_id used when replicating from the primary in direct replication mode.
codec
- Type: enum
- Mandatory: No
- Dynamic: No
- Values:
null,deflate - Default:
null
The compression codec to use. By default, the avrorouter does not use compression.
This parameter takes one of the following two values; null or deflate. These are the mandatory compression algorithms required by the Avro specification. For more information about the compression types, refer to the Avro specification.
match and exclude
- Type: regex
- Mandatory: No
- Dynamic: No
- Default:
""
These regular expression settings filter events for processing depending on table names. Avrorouter does not support the options-parameter for regular expressions.
To prevent excessive matching of similarly named tables, surround each table
name with the ^ and $ tokens. For example, to match the test.clients table
but not test.clients_old table use match=^test[.]clients$. For multiple
tables, surround each table in parentheses and add a pipe character between
them: match=(^test[.]t1$)|(^test[.]t2$).
binlogdir
- Type: path
- Mandatory: No
- Dynamic: No
- Default:
/var/lib/maxscale/
The location of the binary log files. This is the first mandatory parameter and it defines where the module will read binlog files from. Read access to this directory is required.
avrodir
- Type: path
- Mandatory: No
- Dynamic: No
- Default:
/var/lib/maxscale/
The location where the Avro files are stored. This is the second mandatory parameter and it governs where the converted files are stored. This directory will be used to store the Avro files, plain-text Avro schemas and other files needed by the avrorouter. The user running MariaDB MaxScale will need both read and write access to this directory.
The avrorouter will also use the avrodir to store various internal files. These files are named avro.index and avro-conversion.ini. By default, the default data directory, /var/lib/maxscale/, is used. Before version 2.1 of MaxScale, the value of binlogdir was used as the default value for avrodir.
filestem
- Type: string
- Mandatory: No
- Dynamic: No
- Default:
mysql-bin
The base name of the binlog files. The binlog files are assumed to follow the naming schema <filestem>.<n> where <n> is the binlog number and <filestem> is the value of this router option.
For example, with the following parameters:
filestem=mybin binlogdir=/var/lib/mysql/binlogs/
The first binlog file the avrorouter would look for is /var/lib/mysql/binlogs/mybin.000001.
start_index
- Type: number
- Mandatory: No
- Dynamic: No
- Default:
1
The starting index number of the binlog file. The default value is 1. For the binlog mysql-bin.000001 the index would be 1, for mysql-bin.000005 the index would be 5.
If you need to start from a binlog file other than 1, you need to set the value of this option to the correct index. The avrorouter will always start from the beginning of the binary log file.
cooperative_replication
- Type: boolean
- Mandatory: No
- Dynamic: No
- Default:
false
Controls whether multiple instances cooperatively replicate from the same cluster. This is a boolean parameter and is disabled by default. It was added in MaxScale 6.0.
When this parameter is enabled and the monitor pointed to by the cluster
parameter supports cooperative monitoring (currently only mariadbmon),
the replication is only active if the monitor owns the cluster it is
monitoring.
With this feature, multiple MaxScale instances can replicate from the same set of servers and only one of them actively processes the replication stream. This allows the avrorouter instances to be made highly-available without having to have them all process the events at the same time.
Whenever an instance that does not own the cluster gains ownership of the cluster, the replication will continue from the latest GTID processed by that instance. This means that if the instance hasn't replicated events that have been purged from the binary logs, the replication cannot continue.
Avro File Related Parameters
These options control how large the Avro file data blocks can get. Increasing or lowering the block size could have a positive effect depending on your use case. For more information about the Avro file format and how it organizes data, refer to the Avro documentation.
The avrorouter will flush a block and start a new one when either group_trx
transactions or group_rows row events have been processed. Changing these
options will also allow more frequent updates to stored data but this
will cause a small increase in file size and search times.
It is highly recommended to keep the block sizes relatively large to allow larger chunks of memory to be flushed to disk at one time. This will make the conversion process noticeably faster.
group_trx
- Type: number
- Mandatory: No
- Dynamic: No
- Default:
1
Controls the number of transactions that are grouped into a single Avro data block.
group_rows
- Type: number
- Mandatory: No
- Dynamic: No
- Default:
1000
Controls the number of row events that are grouped into a single Avro data block.
block_size
- Type: size
- Mandatory: No
- Dynamic: Yes
- Default:
16KiB
The Avro data block size in bytes. The default is 16 kilobytes. Increase this value if individual events in the binary logs are very large. The value is a size type parameter which means that it can also be defined with an SI suffix. Refer to the Configuration Guide for more details about size type parameters and how to use them.
max_file_size
- Type: size
- Mandatory: No
- Dynamic: No
- Default: 0
If the size of a single Avro data file exceeds this limit, the avrorouter will rotate to a new file. This is done by closing the existing file and creating a new one with the next version number. By default the avrorouter does not rotate files based on their size. Setting the value to 0 disables file rotation based on size.
This uses the size of the file as reported by the operating system. The check for the file size is done after a transaction has been processed which means that large transactions can still cause the file size to exceed the given limit.
File rotation only works with the direct replication mode. The legacy file based replication mode does not support this.
max_data_age
- Type: duration
- Mandatory: No
- Dynamic: No
- Default: 0s
When enabled, the avrorouter will automatically purge any files that only have data that is older than the given limit. This means that all data files with at least one event that is newer than the configured limit will not be removed, even if the age of all the other events is above the limit. The purge operation is only done when a file rotation takes place (either manual or automatic) or when a schema change is detected.
This parameter is best combined with max_file_size to provide automatic
removal of stale data.
Automatic file purging only works with the direct replication mode. The legacy file based replication mode does not support this.
Example configuration
[replication-router] type=service router=binlogrouter router_options=server-id=4000,binlogdir=/var/lib/mysql,filestem=binlog user=maxuser password=maxpwd [avro-router] type=service router=avrorouter binlogdir=/var/lib/mysql filestem=binlog avrodir=/var/lib/maxscale
Module commands
Read Module Commands documentation for details about module commands.
The avrorouter supports the following module commands.
avrorouter::convert SERVICE {start | stop}
Start or stop the binary log to Avro conversion. The first parameter is the name of the service to stop and the second parameter tells whether to start the conversion process or to stop it.
avrorouter::purge SERVICE
This command will delete all files created by the avrorouter. This includes all .avsc schema files and .avro data files as well as the internal state tracking files. Use this to completely reset the conversion process.
Note: Once the command has completed, MaxScale must be restarted to restart
the conversion process. Issuing a convert start command will not work.
WARNING: You will lose any and all converted data when this command is executed.
Files Created by the Avrorouter
The avrorouter creates two files in the location pointed by avrodir: avro.index and avro-conversion.ini. The avro.index file is used to store the locations of the GTIDs in the .avro files. The avro-conversion.ini contains the last converted position and GTID in the binlogs. If you need to reset the conversion process, delete these two files and restart MaxScale.
Resetting the Conversion Process
To reset the binlog conversion process, issue the purge module command by
executing it via MaxCtrl and stop MaxScale. If manually created schema files
were used, they need to be recreated once MaxScale is stopped. After stopping
MaxScale and optionally creating the schema files, the conversion process can be
started by starting MaxScale.
Stopping the Avrorouter
The safest way to stop the avrorouter when used with the binlogrouter is to follow the following steps:
- Issue
STOP SLAVEon the binlogrouter - Wait for the avrorouter to process all files
- Stop MaxScale with
systemctl stop maxscale
This guarantees that the conversion process halts at a known good position in the latest binlog file.
Example Client
The avrorouter comes with an example client program, cdc.py, written in Python 3. This client can connect to a MaxScale configured with the CDC protocol and the avrorouter.
Before using this client, you will need to install the Python 3 interpreter and add users to the service with the cdc_users.py script. Fore more details about the user creation, please refer to the CDC Protocol and CDC Users documentation.
Read the output of cdc.py --help for a full list of supported options
and a short usage description of the client program.
Avro Schema Generator
The avrorouter needs to have access to the CREATE TABLE statement for all tables for which there are data events in the binary logs. If the CREATE TABLE statements for the tables aren't present in the current binary logs, the schema files must be created.
In the direct replication mode, avrorouter will automatically create the missing
schema files by connecting to the database and executing a SHOW CREATE TABLE
statement. If a connection cannot be made or the service user lacks the
permission, an error will be logged and the data events for that table will not
be processed.
For the legacy binlog mode, the files must be generated with a schema file generator. There are currently two methods to generate the .avsc schema files.
Simple Schema Generator
The cdc_one_schema.py generates a schema file for a single table by reading a
tab separated list of field and type names from the standard input. This is the
recommended schema generation tool as it does not directly communicate with the
database thus making it more flexible.
The only requirement to run the script is that a Python interpreter is installed.
To use this script, pipe the output of the mysql command line into the
cdc_one_schema.py script:
mysql -ss -u <user> -p -h <host> -P <port> -e 'DESCRIBE `<database>`.`<table>`'|./cdc_one_schema.py <database> <table>
Replace the <user>, <host>, <port>, <database> and <table> with
appropriate values and run the command. Note that the -ss parameter is
mandatory as that will generate the tab separated output instead of the default
pretty-printed output.
An .avsc file named after the database and table name will be generated in the
current working directory. Copy this file to the location pointed by the
avrodir parameter of the avrorouter.
Alternatively, you can also copy the output of the mysql command to a file and
feed it into the script if you cannot execute the SQL command directly:
# On the database server mysql -ss -u <user> -p -h <host> -P <port> -e 'DESCRIBE `<database>`.`<table>`' > schema.tsv # On the MaxScale server ./cdc_one_schema.py <database> <table> < schema.tsv
If you want to use a specific Python interpreter instead of the one found in the
search path, you can modify the first line of the script from #!/usr/bin/env
python to #!/path/to/python where /path/to/python is the absolute path to
the Python interpreter (both Python 2 and Python 3 can be used).
Python Schema Generator
usage: cdc_schema.py [--help] [-h HOST] [-P PORT] [-u USER] [-p PASSWORD] DATABASE
The cdc_schema.py executable is installed as a part of MaxScale. This is a Python 3 script that generates Avro schema files from an existing database.
The script will generate the .avsc schema files into the current directory. Run
the script for all required databases copy the generated .avsc files to the
directory where the avrorouter stores the .avro files (the value of avrodir).
Go Schema Generator
The cdc_schema.go example Go program is provided with MaxScale. This file
can be used to create Avro schemas for the avrorouter by connecting to a
database and reading the table definitions. You can find the file in MaxScale's
share directory in /usr/share/maxscale/.
You'll need to install the Go compiler and run go get to resolve Go
dependencies before you can use the cdc_schema program. After resolving the
dependencies you can run the program with go run cdc_schema.go. The program
will create .avsc files in the current directory. These files should be moved
to the location pointed by the avrodir option of the avrorouter if they are
to be used by the router itself.
Read the output of go run cdc_schema.go -help for more information on how
to run the program.
Examples
The Avrorouter Tutorial shows you how the Avrorouter works with the Binlog Server to convert binlogs from a primary server into easy to process Avro data.
Here is a simple configuration example which reads binary logs locally from
/var/lib/mysql/ and stores them as Avro files in /var/lib/maxscale/avro/.
The service has one listener listening on port 4001 for CDC protocol clients.
[avro-converter]
type=service
router=avrorouter
user=myuser
password=mypasswd
router_options=binlogdir=/var/lib/mysql/,
filestem=binlog,
avrodir=/var/lib/maxscale/avro/
[avro-listener]
type=listener
service=avro-converter
protocol=CDC
port=4001
Here is an example how you can query for data in JSON format using the cdc.py Python script. It queries the table test.mytable for all change records.
cdc.py --user=myuser --password=mypasswd --host=127.0.0.1 --port=4001 test.mytable
You can then combine it with the cdc_kafka_producer.py to publish these change records to a Kafka broker.
cdc.py --user=myuser --password=mypasswd --host=127.0.0.1 --port=4001 test.mytable | cdc_kafka_producer.py --kafka-broker 127.0.0.1:9092 --kafka-topic test.mytable
For more information on how to use these scripts, see the output of cdc.py -h
and cdc_kafka_producer.py -h.
Building Avrorouter
To build the avrorouter from source, you will need the
Avro C library, liblzma,
the Jansson library and sqlite3 development
headers. When configuring MaxScale with CMake, you will need to add
-DBUILD_CDC=Y to build the CDC module set.
The Avro C library needs to be build with position independent code enabled. You can do this by adding the following flags to the CMake invocation when configuring the Avro C library.
-DCMAKE_C_FLAGS=-fPIC -DCMAKE_CXX_FLAGS=-fPIC
For more details about building MaxScale from source, please refer to the Building MaxScale from Source Code document.
Router Diagnostics
The router_diagnostics output for an avrorouter service contains the following
fields.
infofile: File where the avrorouter stores the conversion process state.avrodir: Directory where avro files are storedbinlogdir: Directory where binlog files are read frombinlog_name: Current binlog namebinlog_pos: Current binlog positiongtid: Current GTIDgtid_timestamp: Current GTID timestampgtid_event_number: Current GTID event number
Limitations
The avrorouter does not support the following data types, conversions or SQL statements:
- BIT
- Fields CAST from integer types to string types
- CREATE TABLE ... AS SELECT statements
The avrorouter does not do any crash recovery. This means that the avro files need to be removed or truncated to valid block lengths before starting the avrorouter.
