Avrorouter Tutorial
Avrorouter Tutorial
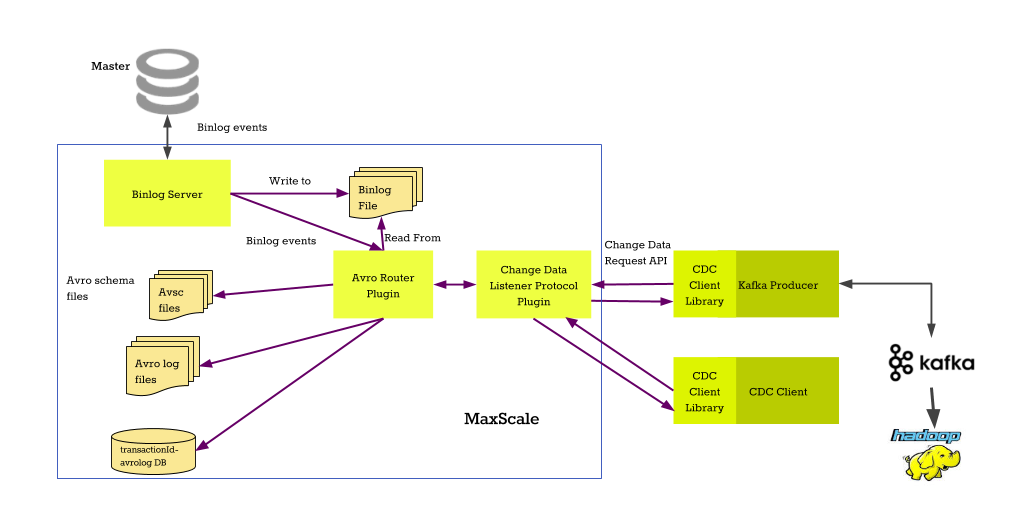
This tutorial is a short introduction to the Avrorouter, how to set it up and how it interacts with the binlogrouter.
The first part configures the services and sets them up for the binary log to Avro file conversion. The second part of this tutorial uses the client listener interface for the avrorouter and shows how to communicate with the the service over the network.
Configuration
Preparing the primary server
The primary server where we will be replicating from needs to have binary logging
enabled, binlog_format set to row and binlog_row_image set to
full. These can be enabled by adding the two following lines to the my.cnf
file of the primary.
binlog_format=row binlog_row_image=full
You can find out more about replication formats from the MariaDB Knowledge Base
Configuring MaxScale
We start by adding two new services into the configuration file. The first service is the binlogrouter service which will read the binary logs from the primary server. The second service will read the binlogs as they are streamed from the primary and convert them into Avro format files.
# The Replication Proxy service [replication-service] type=service router=binlogrouter server_id=4000 master_id=3000 filestem=binlog user=maxuser password=maxpwd # The Avro conversion service [avro-service] type=service router=avrorouter source=replication-service filestem=binlog start_index=15 # The listener for the replication-service [replication-listener] type=listener service=replication-service port=3306 # The client listener for the avro-service [avro-listener] type=listener service=avro-service protocol=CDC port=4001
The source parameter in the avro-service points to the replication-service
we defined before. This service will be the data source for the avrorouter. The
filestem is the prefix in the binlog files and start_index is the binlog
number to start from. With these parameters, the avrorouter will start reading
events from binlog binlog.000015.
Note that the filestem and start_index must point to the file that is the
first binlog that the binlogrouter will replicate. For example, if the first
file you are replicating is my-binlog-file.001234, set the parameters to
filestem=my-binlog-file and start_index=1234.
For more information on the avrorouter options, read the Avrorouter Documentation.
Preparing the data in the primary server
Before starting the MaxScale process, we need to make sure that the binary logs
of the primary server contain the DDL statements that define the table
layouts. What this means is that the CREATE TABLE statements need to be in the
binary logs before the conversion process is started.
If the binary logs contain data modification events for tables that aren't created in the binary logs, the Avro schema of the table needs to be manually created. There are multiple ways to do this:
-
Dump the database to a replica, configure it to replicate from the primary and point MaxScale to this replica (this is the recommended method as it requires no extra steps)
-
Use the cdc_schema Go utility and copy the generated .avsc files to the avrodir
-
Use the Python version of the schema generator and copy the generated .avsc files to the avrodir
If you used the schema generator scripts, all Avro schema files for tables that
are not created in the binary logs need to be in the location pointed to by the
avrodir parameter. The files use the following naming:
<database>.<table>.<schema_version>.avsc. For example, the schema file name of
the test.t1 table would be test.t1.0000001.avsc.
Starting MariaDB MaxScale
The next step is to start MariaDB MaxScale and set up the binlogrouter. We do that by connecting to the MySQL listener of the replication_router service and executing a few commands.
CHANGE MASTER TO MASTER_HOST='172.18.0.1',
MASTER_PORT=3000,
MASTER_LOG_FILE='binlog.000015',
MASTER_LOG_POS=4,
MASTER_USER='maxuser',
MASTER_PASSWORD='maxpwd';
START SLAVE;
NOTE: GTID replication is not currently supported and file-and-position replication must be used.
This will start the replication of binary logs from the primary server at
172.18.0.1 listening on port 3000. The first file that the binlogrouter
replicates is binlog.000015. This is the same file that was configured as the
starting file in the avrorouter.
For more details about the SQL commands, refer to the Binlogrouter documentation.
After the binary log streaming has started, the avrorouter will automatically start processing the binlogs.
Creating and Processing Data
Next, create a simple test table and populated it with some data by executing the following statements.
CREATE TABLE test.t1 (id INT); INSERT INTO test.t1 VALUES (1), (2), (3), (4), (5), (6), (7), (8), (9), (10);
To use the cdc.py command line client to connect to the CDC service, we must first create a user. This can be done via maxctrl by executing the following command.
maxctrl call command cdc add_user avro-service maxuser maxpwd
This will create the maxuser:maxpwd credentials which can then be used to
request a JSON data stream of the test.t1 table that was created earlier.
cdc.py -u maxuser -p maxpwd -h 127.0.0.1 -P 4001 test.t1
The output is a stream of JSON events describing the changes done to the database.
{"namespace": "MaxScaleChangeDataSchema.avro", "type": "record", "name": "ChangeRecord", "fields": [{"name": "domain", "type": "int"}, {"name": "server_id", "type": "int"}, {"name": "sequence", "type": "int"}, {"name": "event_number", "type": "int"}, {"name": "timestamp", "type": "int"}, {"name": "event_type", "type": {"type": "enum", "name": "EVENT_TYPES", "symbols": ["insert", "update_before", "update_after", "delete"]}}, {"name": "id", "type": "int", "real_type": "int", "length": -1}]}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 1, "timestamp": 1537429419, "event_type": "insert", "id": 1}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 2, "timestamp": 1537429419, "event_type": "insert", "id": 2}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 3, "timestamp": 1537429419, "event_type": "insert", "id": 3}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 4, "timestamp": 1537429419, "event_type": "insert", "id": 4}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 5, "timestamp": 1537429419, "event_type": "insert", "id": 5}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 6, "timestamp": 1537429419, "event_type": "insert", "id": 6}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 7, "timestamp": 1537429419, "event_type": "insert", "id": 7}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 8, "timestamp": 1537429419, "event_type": "insert", "id": 8}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 9, "timestamp": 1537429419, "event_type": "insert", "id": 9}
{"domain": 0, "server_id": 3000, "sequence": 11, "event_number": 10, "timestamp": 1537429419, "event_type": "insert", "id": 10}
The first record is always the JSON format schema for the table describing the types and names of the fields. All records that follow it represent the changes that have happened on the database.
