MaxScale 24.08 Beta MariaDB Monitor
MariaDB Monitor
- MariaDB Monitor
- Overview
- Required Grants
- Primary selection
- Configuration
- Common Monitor Parameters
- MariaDB Monitor optional parameters
- Cluster manipulation operations
- Operation details
- Manual activation
- Automatic activation
- Limitations and requirements
- External primary support
- Configuration parameters
- auto_failover
- auto_rejoin
- switchover_on_low_disk_space
- enforce_simple_topology
- replication_user and replication_password
- replication_master_ssl
- replication_custom_options
- failover_timeout and switchover_timeout
- verify_master_failure and master_failure_timeout
- servers_no_promotion
- promotion_sql_file and demotion_sql_file
- handle_events
- Cooperative monitoring
- Primary server write test
- Backup operations
- ColumnStore commands
- Other commands
- Troubleshooting
- Using the MariaDB Monitor With Binlogrouter
Overview
MariaDB Monitor monitors a Primary-Replica replication cluster. It probes the state of the backends and assigns server roles such as primary and replica, which are used by the routers when deciding where to route a query. It can also modify the replication cluster by performing failover, switchover and rejoin. Backend server versions older than MariaDB/MySQL 5.5 are not supported. Failover and other similar operations require MariaDB 10.4 or later.
Up until MariaDB MaxScale 2.2.0, this monitor was called MySQL Monitor.
Required Grants
The monitor user requires the following grant:
CREATE USER 'maxscale'@'maxscalehost' IDENTIFIED BY 'maxscale-password'; GRANT REPLICATION CLIENT ON *.* TO 'maxscale'@'maxscalehost';
In MariaDB Server versions 10.5.0 to 10.5.8, the monitor user instead requires REPLICATION SLAVE ADMIN:
GRANT REPLICATION SLAVE ADMIN ON *.* TO 'maxscale'@'maxscalehost';
In MariaDB Server 10.5.9 and later, REPLICA MONITOR is required:
GRANT REPLICA MONITOR ON *.* TO 'maxscale'@'maxscalehost';
If the monitor needs to query server disk space (i.e. disk_space_threshold is
set), then the FILE-grant is required with MariaDB Server versions 10.4.7,
10.3.17, 10.2.26 and 10.1.41 and later.
GRANT FILE ON *.* TO 'maxscale'@'maxscalehost';
MariaDB Server 10.5.2 introduces CONNECTION ADMIN. This is recommended since it allows the monitor to log in even if server connection limit has been reached.
GRANT CONNECTION ADMIN ON *.* TO 'maxscale'@'maxscalehost';
Cluster Manipulation Grants
If cluster manipulation operations are used, the following additional grants are required:
GRANT SUPER, RELOAD, PROCESS, SHOW DATABASES, EVENT ON *.* TO 'maxscale'@'maxscalehost'; GRANT SELECT ON mysql.user TO 'maxscale'@'maxscalehost';
MariaDB 10.5.2 and later require read access to mysql.global_priv:
GRANT SELECT ON mysql.global_priv TO 'maxscale'@'maxscalehost';
As of MariaDB Server 11.0.1, the SUPER-privilege no longer contains several of its former sub-privileges. These must be given separately.
GRANT RELOAD, PROCESS, SHOW DATABASES, EVENT, SET USER, READ_ONLY ADMIN ON *.* TO 'maxscale'@'maxscalehost'; GRANT REPLICATION SLAVE ADMIN, BINLOG ADMIN, CONNECTION ADMIN ON *.* TO 'maxscale'@'maxscalehost'; GRANT SELECT ON mysql.user TO 'maxscale'@'maxscalehost'; GRANT SELECT ON mysql.global_priv TO 'maxscale'@'maxscalehost';
If a separate replication user is defined (with replication_user and
replication_password), it requires the following grant:
CREATE USER 'replication'@'replicationhost' IDENTIFIED BY 'replication-password'; GRANT REPLICATION SLAVE ON *.* TO 'replication'@'replicationhost';
Primary selection
Only one backend can be primary at any given time. A primary must be running
(successfully connected to by the monitor) and its read_only-setting must be
off. A primary may not be replicating from another server in the monitored
cluster unless the primary is part of a multiprimary group. Primary selection
prefers to select the server with the most replicas, possibly in multiple
replication layers. Only replicas reachable by a chain of running relays or
directly connected to the primary count. When multiple servers are tied for
primary status, the server which appears earlier in the servers-setting of the
monitor is selected.
Servers in a cyclical replication topology (multiprimary group) are interpreted as having all the servers in the group as replicas. Even from a multiprimary group only one server is selected as the overall primary.
After a primary has been selected, the monitor prefers to stick with the choice even if other potential primaries with more replica servers are available. Only if the current primary is clearly unsuitable does the monitor try to select another primary. An existing primary turns invalid if:
- It is unwritable (read_only is on).
- It has been down for more than failcount monitor passes and has no running replicas. Running replicas behind a downed relay count. A replica in this context is any server with at least a partially running replication connection (either io or sql thread is running). The replicas must also be down for more than failcount monitor passes to allow new master selection.
- It did not previously replicate from another server in the cluster but it is now replicating.
- It was previously part of a multiprimary group but is no longer, or the multiprimary group is replicating from a server not in the group.
Cases 1 and 2 cover the situations in which the DBA, an external script or even another MaxScale has modified the cluster such that the old primary can no longer act as primary. Cases 3 and 4 are less severe. In these cases the topology has changed significantly and the primary should be re-selected, although the old primary may still be the best choice.
The primary change described above is different from failover and switchover described in section Failover, switchover and auto-rejoin. A primary change only modifies the server roles inside MaxScale but does not modify the cluster other than changing the targets of read and write queries. Failover and switchover perform a primary change on their own.
As a general rule, it's best to avoid situations where the cluster has multiple standalone servers, separate primary-replica pairs or separate multiprimary groups. Due to primary invalidation rule 2, a standalone primary can easily lose the primary status to another valid primary if it goes down. The new primary probably does not have the same data as the previous one. Non-standalone primaries are less vulnerable, as a single running replica or multiprimary group member will keep the primary valid even when down.
Configuration
A minimal configuration for a monitor requires a set of servers for monitoring and a username and a password to connect to these servers.
[MyMonitor] type=monitor module=mariadbmon servers=server1,server2,server3 user=myuser password=mypwd
From MaxScale 2.2.1 onwards, the module name is mariadbmon instead of
mysqlmon. The old name can still be used.
The grants required by user depend on which monitor features are used. A full
list of the grants can be found in the Required Grants
section.
Common Monitor Parameters
For a list of optional parameters that all monitors support, read the Monitor Common document.
MariaDB Monitor optional parameters
These are optional parameters specific to the MariaDB Monitor. Failover, switchover and rejoin-specific parameters are listed in their own section. Rebuild-related parameters are described in the Rebuild server-section. ColumnStore parameters are described in the ColumnStore commands-section.
assume_unique_hostnames
Boolean, default: ON. When active, the monitor assumes that server hostnames and
ports are consistent between the server definitions in the MaxScale
configuration file and the "SHOW ALL SLAVES STATUS" outputs of the servers
themselves. Specifically, the monitor assumes that if server A is replicating
from server B, then A must have a replica connection with Master_Host and
Master_Port equal to B's address and port in the configuration file. If this
is not the case, e.g. an IP is used in the server while a hostname is given in
the file, the monitor may misinterpret the topology. The monitor attempts name
resolution on the addresses if a simple string comparison
does not find a match. Using exact matching addresses is, however, more
reliable. In MaxScale 24.02.0, an alternative IP or hostname for a server can be
given in private_address.
This setting must be ON to use any cluster operation features such as failover or switchover, because MaxScale uses the addresses and ports in the configuration file when issuing "CHANGE MASTER TO"-commands.
If the network configuration is such that the addresses MaxScale uses to connect
to backends are different from the ones the servers use to connect to each
other and private_address is not used, assume_unique_hostnames should be
set to OFF. In this mode, MaxScale uses server id:s it queries from
the servers and the Master_Server_Id fields of the replica connections
to deduce which server is replicating from which. This is not perfect though,
since MaxScale doesn't know the id:s of servers it has
never connected to (e.g. server has been down since MaxScale was started). Also,
the Master_Server_Id-field may have an incorrect value if the replica connection
has not been established. MaxScale will only trust the value if the monitor has
seen the replica connection IO thread connected at least once. If this is not the
case, the replica connection is ignored.
private_address
String. This is an optional server setting, yet documented here since it's only used by MariaDB Monitor. If not set, the normal server address setting is used.
Defines an alternative IP-address or hostname for the server for use with replication. Whenever MaxScale modifies replication (e.g. during switchover), the private address is given as Master_Host to "CHANGE MASTER TO"-commands. Also, when detecting replication, any Master_Host-values from "SHOW SLAVE STATUS"-queries are compared to the private addresses of configured servers if the normal address doesn't match.
This setting is useful if replication and application traffic are separated to different network interfaces.
master_conditions
Enum, default: primary_monitor_master, disk_space_ok. Designate additional conditions for Master-status, i.e qualified for read and write queries.
Normally, if a suitable primary candidate server is found as described in Primary selection, MaxScale designates it Master. master_conditions sets additional conditions for a primary server. This setting is an enum, allowing multiple conditions to be set simultaneously. Conditions 2, 3 and 4 refer to replica servers. A single replica must fulfill all of the given conditions for the primary to be viable.
If the primary candidate fails master_conditions but fulfills slave_conditions, it may be designated Slave instead.
The available conditions are:
- none : No additional conditions
- connecting_slave : At least one immediate replica (not behind relay) is attempting to replicate or is replicating from the primary (Slave_IO_Running is 'Yes' or 'Connecting', Slave_SQL_Running is 'Yes'). A replica with incorrect replication credentials does not count. If the replica is currently down, results from the last successful monitor tick are used.
- connected_slave : Same as above, with the difference that the replication connection must be up (Slave_IO_Running is 'Yes'). If the replica is currently down, results from the last successful monitor tick are used.
- running_slave : Same as connecting_slave, with the addition that the replica must also be Running.
- primary_monitor_master : If this MaxScale is cooperating with another MaxScale and this is the secondary MaxScale, require that the candidate primary is selected also by the primary MaxScale.
- disk_space_ok : The candidate primary must not be low on disk space. This option only takes effect if disk space check is enabled. Added in MaxScale 23.08.5.
The default value of this setting is
master_requirements=primary_monitor_master,disk_space_ok to ensure that both
monitors use the same primary server when cooperating and that the primary is
not out of disk space.
For example, to require that the primary must have a replica which is both connected and running, set
master_conditions=connected_slave,running_slave
slave_conditions
Enum, default: none. Designate additional conditions for Slave-status, i.e qualified for read queries.
Normally, a server is Slave if it is at least attempting to replicate from the primary candidate or a relay (Slave_IO_Running is 'Yes' or 'Connecting', Slave_SQL_Running is 'Yes', valid replication credentials). The primary candidate does not necessarily need to be writable, e.g. if it fails its master_conditions. slave_conditions sets additional conditions for a replica server. This setting is an enum, allowing multiple conditions to be set simultaneously.
The available conditions are:
- none : No additional conditions. This is the default value.
- linked_master : The replica must be connected to the primary (Slave_IO_Running and Slave_SQL_Running are 'Yes') and the primary must be Running. The same applies to any relays between the replica and the primary.
- running_master : The primary must be running. Relays may be down.
- writable_master : The primary must be writable, i.e. labeled Master.
- primary_monitor_master : If this MaxScale is cooperating with another MaxScale and this is the secondary MaxScale, require that the candidate primary is selected also by the primary MaxScale.
- disk_space_ok : The replica must not be low on disk space. This option only takes effect if disk space check is enabled. Added in MaxScale 23.08.5.
For example, to require that the primary server of the cluster must be running and writable for any servers to have Slave-status, set
slave_conditions=running_master,writable_master
failcount
Number of consecutive monitor passes a primary server must be down before it is
considered failed. If automatic failover is enabled (auto_failover=true), it
may be performed at this time. A value of 0 or 1 enables immediate failover.
If automatic failover is not possible, the monitor will try to search for another server to fulfill the primary role. See section Primary selection for more details. Changing the primary may break replication as queries could be routed to a server without previous events. To prevent this, avoid having multiple valid primary servers in the cluster.
The default value is 5 failures.
The worst-case delay between the primary failure and the start of the failover
can be estimated by summing up the timeout values and monitor_interval and
multiplying that by failcount:
(monitor_interval + backend_connect_timeout) * failcount
enforce_writable_master
This feature is disabled by default. If set to ON, the monitor attempts to disable the read_only-flag on the primary when seen. The flag is checked every monitor tick. The monitor user requires the SUPER-privilege for this feature to work.
Typically, the primary server should never be in read-only-mode. Such a situation may arise due to misconfiguration or accident, or perhaps if MaxScale crashed during switchover.
When this feature is enabled, setting the primary manually to read_only will no longer cause the monitor to search for another primary. The primary will instead for a moment lose its [Master]-status (no writes), until the monitor again enables writes on the primary. When starting from scratch, the monitor still prefers to select a writable server as primary if possible.
enforce_read_only_slaves
This feature is disabled by default. If set to ON, the monitor attempts to enable the read_only-flag on any writable replica server. The flag is checked every monitor tick. The monitor user requires the SUPER-privilege (or READ_ONLY ADMIN) for this feature to work. While the read_only-flag is ON, only users with the SUPER-privilege (or READ_ONLY ADMIN) can write to the backend server. If temporary write access is required, this feature should be disabled before attempting to disable read_only manually. Otherwise, the monitor will quickly re-enable it.
read_only won't be enabled on the master server, even if it has lost [Master]-status due to master_conditions and is marked [Slave].
enforce_read_only_servers
Boolean, default: false. Works similar to enforce_read_only_slaves except will set read_only on any writable server that is not the primary and not in maintenance (a superset of the servers altered by enforce_read_only_slaves).
The monitor user requires the SUPER-privilege (or READ_ONLY ADMIN) for this feature to work. If the cluster has no valid primary or primary candidate, read_only is not set on any server as it is unclear which servers should be altered.
maintenance_on_low_disk_space
This feature is enabled by default. If a running server that is not the primary or a relay primary is out of disk space the server is set to maintenance mode. Such servers are not used for router sessions and are ignored when performing a failover or other cluster modification operation. See the general monitor parameters disk_space_threshold and disk_space_check_interval on how to enable disk space monitoring.
Once a server has been put to maintenance mode, the disk space situation of that server is no longer updated. The server will not be taken out of maintenance mode even if more disk space becomes available. The maintenance flag must be removed manually:
maxctrl clear server server2 Maint
cooperative_monitoring_locks
Using this setting is recommended when multiple MaxScales are monitoring the same backend cluster. When enabled, the monitor attempts to acquire exclusive locks on the backend servers. The monitor considers itself the primary monitor if it has a majority of locks. The majority can be either over all configured servers or just over running servers. See Cooperative monitoring for more details on how this feature works and which value to use.
Allowed values:
1. none Default value, no locking.
2. majority_of_all Primary monitor requires majority of locks, even counting
servers which are [Down].
3. majority_of_running Primary monitor requires majority of locks over
[Running] servers.
This setting is separate from the global MaxScale setting passive. If passive is set, cluster operations are disabled even if monitor has acquired the locks. Generally, it's best not to mix cooperative monitoring with the passive-setting.
script_max_replication_lag
Integer, default: -1. Defines a replication lag limit in seconds for launching the monitor script configured in the script-parameter. If the replication lag of a server goes above this limit, the script is ran with the $EVENT-placeholder replaced by "rlag_above". If the lag goes back below the limit, the script is ran again with replacement "rlag_below".
Negative values disable this feature. For more information on monitor scripts, see general monitor documentation.
Cluster manipulation operations
MariaDB Monitor can perform several operations that modify the replication topology. The supported operations are:
- failover, which replaces a failed primary with a replica
- failover-safe, which replaces a failed primary with a replica only if no data is clearly lost
- switchover, which swaps a running primary with a replica
- switchover-force, which swaps a running primary with a replica, ignoring most errors
- async-switchover, which schedules a switchover and returns
- rejoin, which directs servers to replicate from the primary
- reset-replication (added in MaxScale 2.3.0), which deletes binary logs and resets gtid:s
See operation details for more information on the implementation of the commands.
The cluster operations require that the monitor user (user) has the following
privileges:
- SUPER, to modify replica connections, set globals such as read_only and kill connections from other super-users
- REPLICATION CLIENT (REPLICATION SLAVE ADMIN in MariaDB Server 10.5), to list replica connections
- RELOAD, to flush binary logs
- PROCESS, to check if the event_scheduler process is running
- SHOW DATABASES and EVENT, to list and modify server events
- SELECT on mysql.user, to see which users have SUPER
- SELECT on mysql.global_priv so see to see which users have READ_ONLY ADMIN
A list of the grants can be found in the Required Grants section.
The privilege system was changed in MariaDB Server 10.5. The effects of this on the MaxScale monitor user are minor, as the SUPER-privilege contains many of the required privileges and is still required to kill connections from other super-users.
In MariaDB Server 11.0.1 and later, SUPER no longer contains all the required grants. The monitor requires:
- READ_ONLY ADMIN, to set read_only
- REPLICA MONITOR and REPLICATION SLAVE ADMIN, to view and manage replication connections
- RELOAD, to flush binary logs
- PROCESS, to check if the event_scheduler process is running
- SHOW DATABASES, EVENT and SET USER, to list and modify server events
- BINLOG ADMIN, to delete binary logs (during reset-replication)
- CONNECTION ADMIN, to kill connections
- SELECT on mysql.user, to see which users have SUPER
- SELECT on mysql.global_priv so see to see which users have READ_ONLY ADMIN
In addition, the monitor needs to know which username and password a
replica should use when starting replication. These are given in
replication_user and replication_password.
The user can define files with SQL statements which are executed on any server
being demoted or promoted by cluster manipulation commands. See the sections on
promotion_sql_file and demotion_sql_file for more information.
The monitor can manipulate scheduled server events when promoting or demoting a
server. See the section on handle_events for more information.
All cluster operations can be activated manually through MaxCtrl. See section Manual activation for more details.
See Limitations and requirements for information on possible issues with failover and switchover.
Operation details
Failover
call command mariadbmon failover MONITOR
Failover replaces a failed primary with a running replica. It does the following:
- Select the most up-to-date replica of the old primary to be the new primary. The
selection criteria is as follows in descending priority:
- gtid_IO_pos (latest event in relay log)
- gtid_current_pos (most processed events)
- log_slave_updates is on
- disk space is not low
- If the new primary has unprocessed relay log items, cancel and try again later.
- Prepare the new primary:
- Remove the replica connection the new primary used to replicate from the old primary.
- Disable the read_only-flag.
- Enable scheduled server events (if event handling is on). Only events that were enabled on the old primary are enabled.
- Run the commands in
promotion_sql_file. - Start replication from external primary if one existed.
- Redirect all other replicas to replicate from the new primary:
- STOP SLAVE and RESET SLAVE
- CHANGE MASTER TO
- START SLAVE
- Check that all replicas are replicating.
Failover is considered successful if steps 1 to 3 succeed, as the cluster then has at least a valid primary server.
Failover-safe
call command mariadbmon failover-safe MONITOR
Failover-safe performs the same steps as a normal failover but refuses to start if it's clear that data would be lost. Dataloss occurs if the primary had data which was not replicated to any replica before the primary went down. MaxScale detects this by looking at the GTIDs of the servers. Because the monitor queries the GTIDs only every monitor interval, this check is inaccurate. If the primary performs a write just before crashing and before MaxScale queries the GTID, data could be lost even with "safe" failover. Thus, this feature mainly protects against situations where the replicas are constantly lagging.
Switchover
call command mariadbmon switchover MONITOR [NEW_PRIMARY] [OLD_PRIMARY]
Switchover swaps a running primary with a running replica. It does the following:
- Prepare the old primary for demotion:
- If
backend_read_timeoutis short, extend it and reconnect. - Stop any external replication.
- Enable the read_only-flag to stop writes from normal users.
- Kill connections from super and read-only admin users since read_only does not affect them. During this step, all writes are blocked with "FLUSH TABLES WITH READ LOCK".
- Disable scheduled server events (if event handling is on).
- Run the commands in
demotion_sql_file. - Flush the binary log ("flush logs") so that all events are on disk.
- Wait a moment to check that gtid is stable.
- If
- Wait for the new primary to catch up with the old primary.
- Promote new primary and redirect replicas as in failover steps 3 and 4. Also redirect the demoted old primary.
- Check that all replicas are replicating.
Similar to failover, switchover is considered successful if the new primary was successfully promoted.
Switchover-force
call command mariadbmon switchover-force MONITOR [NEW_PRIMARY] [OLD_PRIMARY]
Switchover-force performs the same steps as a normal switchover but ignores any errors on the old primary. Switchover-force also does not expect the new primary to reach the gtid-position of the old, as the old primary could be receiving more events constantly. Thus, switchover-force may lose events.
Rejoin
call command mariadbmon rejoin MONITOR OLD_PRIMARY
Rejoin joins a standalone server to the cluster or redirects a replica replicating from a server other than the primary. A standalone server is joined by:
- Run the commands in
demotion_sql_file. - Enable the read_only-flag.
- Disable scheduled server events (if event handling is on).
- Start replication: CHANGE MASTER TO and START SLAVE.
A server which is replicating from the wrong primary is redirected simply with STOP SLAVE, RESET SLAVE, CHANGE MASTER TO and START SLAVE commands.
Reset Replication
maxctrl call command mariadbmon reset-replication MONITOR [NEW_PRIMARY]
Reset-replication (added in MaxScale 2.3.0) deletes binary logs and resets gtid:s. This destructive command is meant for situations where the gtid:s in the cluster are out of sync while the actual data is known to be in sync. The operation proceeds as follows:
- Reset gtid:s and delete binary logs on all servers:
- Stop (STOP SLAVE) and delete (RESET SLAVE ALL) all replica connections.
- Enable the read_only-flag.
- Disable scheduled server events (if event handling is on).
- Delete binary logs (RESET MASTER).
- Set the sequence number of gtid_slave_pos to zero. This also affects gtid_current_pos.
- Prepare new primary:
- Disable the read_only-flag.
- Enable scheduled server events (if event handling is on). Events are only enabled if the cluster had a primary server when starting the reset-replication operation. Only events that were enabled on the previous primary are enabled on the new.
- Direct other servers to replicate from the new primary as in the other operations.
Manual activation
Cluster operations can be activated manually through the REST API or MaxCtrl. The commands are only performed when MaxScale is in active mode. The commands generally match their automatic versions. The exception is rejoin, in which the manual command allows rejoining even when the joining server has empty gtid:s. This rule allows the user to force a rejoin on a server without binary logs.
All commands require the monitor instance name as the first parameter. Failover selects the new primary server automatically and does not require additional parameters. Rejoin requires the name of the joining server as second parameter. Replication reset accepts the name of the new primary server as second parameter. If not given, the current primary is selected.
Switchover takes one to three parameters. If only the monitor name is given, switchover will autoselect both the replica to promote and the current primary as the server to be demoted. If two parameters are given, the second parameter is interpreted as the replica to promote. If three parameters are given, the third parameter is interpreted as the current primary. The user-given current primary is compared to the primary server currently deduced by the monitor and if the two are unequal, an error is given.
Example commands are below:
maxctrl call command mariadbmon failover MyMonitor maxctrl call command mariadbmon failover-safe MyMonitor maxctrl call command mariadbmon rejoin MyMonitor OldPrimaryServ maxctrl call command mariadbmon reset-replication MyMonitor maxctrl call command mariadbmon reset-replication MyMonitor NewPrimaryServ maxctrl call command mariadbmon switchover MyMonitor maxctrl call command mariadbmon switchover MyMonitor NewPrimaryServ maxctrl call command mariadbmon switchover MyMonitor NewPrimaryServ OldPrimaryServ maxctrl call command mariadbmon switchover-force MyMonitor NewPrimaryServ
The commands follow the standard module command syntax. All require the monitor configuration name (MyMonitor) as the first parameter. For switchover, the last two parameters define the server to promote (NewPrimaryServ) and the server to demote (OldPrimaryServ). For rejoin, the server to join (OldPrimaryServ) is required. Replication reset requires the server to promote (NewPrimaryServ).
It is safe to perform manual operations even with automatic failover, switchover or rejoin enabled since automatic operations cannot happen simultaneously with manual ones.
When a cluster modification is initiated via the REST-API, the URL path is of the form:
/v1/maxscale/modules/mariadbmon/<operation>?<monitor-name>&<server-name1>&<server-name2>
<operation>is the name of the command e.g. failover, switchover, rejoin or reset-replication.<monitor-name>is the monitor name from the MaxScale configuration file.<server-name1>and<server-name2>are server names as described above for MaxCtrl. Only switchover accepts both, failover doesn't need any and both rejoin and reset-replication accept one.
Given a MaxScale configuration file like
[Cluster1] type=monitor module=mariadbmon servers=server1, server2, server3, server 4 ...
with the assumption that server2 is the current primary, then the URL
path for making server4 the new primary would be:
/v1/maxscale/modules/mariadbmon/switchover?Cluster1&server4&server2
Example REST-API paths for other commands are listed below.
/v1/maxscale/modules/mariadbmon/failover?Cluster1 /v1/maxscale/modules/mariadbmon/rejoin?Cluster1&server3 /v1/maxscale/modules/mariadbmon/reset-replication?Cluster1&server3
Queued switchover
Most cluster modification commands wait until the operation either succeeds or fails. async-switchover is an exception, as it returns immediately. Otherwise async-switchover works identical to a normal switchover command. Use the module command fetch-cmd-result to view the result of the queued command. fetch-cmd-result returns the status or result of the latest manual command, whether queued or not.
maxctrl call command mariadbmon async-switchover Cluster1
OK
maxctrl call command mariadbmon fetch-cmd-result Cluster1
{
"links": {
"self": "http://localhost:8989/v1/maxscale/modules/mariadbmon/fetch-cmd-result"
},
"meta": "switchover completed successfully."
}
Switchover with key-value arguments
As of MaxScale 24.08.0, switchover can be launched using an alternate command syntax which passes arguments as key-value pairs. This allows for greater flexibility as a variable number of arguments can be easily defined in the call. This alternative form of switchover accepts the following arguments:
| argument | type | default | description |
|---|---|---|---|
| monitor | monitor | none (mandatory) | Monitor name |
| new_primary | server | empty (autoselect) | Which server to promote |
| old_primary | server | empty (autoselect) | Which server to demote |
| async | boolean | false | Run command asynchronously |
| force | boolean | false | Ignore most errors |
| old_primary_maint | boolean | false | Leave old primary to maintenance |
The key-value syntax thus supports the same features as the old switchover, async-switchover and switchover-force-commands.
maxctrl call command mariadbmon switchover monitor=MyMonitor new_primary=MyServer2 async=1 force=1
In addition, key-value argument passing supports old_primary_maint. This
feature leaves the old primary server in maintenance mode without replication.
This is useful when performing rolling MariaDB Server version upgrades. After
all replicas have been upgraded, switch out the old primary with
old_primary_maint=1 to promote one of the replicas while leaving the old
primary as standalone.
maxctrl call command mariadbmon switchover monitor=MyMonitor old_primary_maint=1
Automatic activation
Failover can activate automatically if auto_failover is on. The activation
begins when the primary has been down at least failcount monitor iterations.
Before modifying the cluster, the monitor checks that all prerequisites for the
failover are fulfilled. If the cluster does not seem ready, an error is printed
and the cluster is rechecked during the next monitor iteration.
Switchover can also activate automatically with the
switchover_on_low_disk_space-setting. The operation begins if the primary
server is low on disk space but otherwise the operating logic is quite similar
to automatic failover.
Rejoin stands for starting replication on a standalone server or redirecting a replica replicating from the wrong primary (any server that is not the cluster primary). The rejoined servers are directed to replicate from the current cluster primary server, forcing the replication topology to a 1-primary-N-replicas configuration.
A server is categorized as standalone if the server has no replica connections, not even stopped ones. A server is replicating from the wrong primary if the replica IO thread is connected but the primary server id seen by the replica does not match the cluster primary id. Alternatively, the IO thread may be stopped or connecting but the primary server host or port information differs from the cluster primary info. These criteria mean that a STOP SLAVE does not yet set a replica as standalone.
With auto_rejoin active, the monitor will try to rejoin any servers matching
the above requirements. Rejoin does not obey failcount and will attempt to
rejoin any valid servers immediately. When activating rejoin manually, the
user-designated server must fulfill the same requirements.
Limitations and requirements
Switchover and failover are meant for simple topologies (one primary and several replicas). Using these commands with complicated topologies (multiple primaries, relays, circular replication) may give unpredictable results and should be tested before use on a production system.
The server cluster is assumed to be well-behaving with no significant
replication lag (within failover_timeout/switchover_timeout) and all
commands that modify the cluster (such as "STOP SLAVE", "CHANGE MASTER",
"START SLAVE") complete in a few seconds (faster than backend_read_timeout
and backend_write_timeout).
The backends must all use GTID-based replication, and the domain id should not change during a switchover or failover. Replicas should not have extra local events so that GTIDs are compatible across the cluster.
Failover cannot be performed if MaxScale was started only after the primary
server went down. This is because MaxScale needs reliable information on the
gtid domain of the cluster and the replication topology in general to properly
select the new primary. enforce_simple_topology=1 relaxes this requirement.
Failover may lose events. If a primary goes down before sending new events to at least one replica, those events are lost when a new primary is chosen. If the old primary comes back online, the other servers have likely moved on with a diverging history and the old primary can no longer join the replication cluster.
To reduce the chance of losing data, use semisynchronous replication. In semisynchronous mode, the primary waits for a replica to receive an event before returning an acknowledgement to the client. This does not yet guarantee a clean failover. If the primary fails after preparing a transaction but before receiving replica acknowledgement, it will still commit the prepared transaction as part of its crash recovery. If the replicas never saw this transaction, the old primary has diverged from the cluster. See Configuring the Master Wait Point for more information. This situation is much less likely in MariaDB Server 10.6.2 and later, as the improved crash recovery logic will delete such transactions.
Even a controlled shutdown of the primary may lose events. The server does not by default wait for all data to be replicated to the replicas when shutting down and instead simply closes all connections. Before shutting down the primary with the intention of having a replica promoted, run switchover first to ensure that all data is replicated. For more information on server shutdown, see Binary Log Dump Threads and the Shutdown Process.
Switchover requires that the cluster is "frozen" for the duration of the operation. This means that no data modifying statements such as INSERT or UPDATE are executed and the GTID position of the primary server is stable. When switchover begins, the monitor sets the global read_only flag on the old primary backend to stop any updates. read_only does not affect users with the SUPER-privilege so any such user can issue writes during a switchover. These writes have a high chance of breaking replication, because the write may not be replicated to all replicas before they switch to the new primary. To prevent this, any users who commonly do updates should NOT have the SUPER-privilege. For even more security, the only SUPER-user session during a switchover should be the MaxScale monitor user. This also applies to users running scheduled server events. Although the monitor by default disables events on the master, an event may already be executing. If the event definer has SUPER-privilege, the event can write to the database even through read_only.
When mixing rejoin with failover/switchover, the backends should have log_slave_updates on. The rejoining server is likely lagging behind the rest of the cluster. If the current cluster primary does not have binary logs from the moment the rejoining server lost connection, the rejoining server cannot continue replication. This is an issue if the primary has changed and the new primary does not have log_slave_updates on.
If an automatic cluster operation such as auto-failover or auto-rejoin fails,
all cluster modifying operations are disabled for failcount monitor iterations,
after which the operation may be retried. Similar logic applies if the cluster is
unsuitable for such operations, e.g. replication is not using GTID.
External primary support
The monitor detects if a server in the cluster is replicating from an external primary (a server that is not monitored by the monitor). If the replicating server is the cluster primary server, then the cluster itself is considered to have an external primary.
If a failover/switchover happens, the new primary server is set to replicate from
the cluster external primary server. The username and password for the replication
are defined in replication_user and replication_password. The address and
port used are the ones shown by SHOW ALL SLAVES STATUS on the old cluster
primary server. In the case of switchover, the old primary also stops replicating
from the external server to preserve the topology.
After failover the new primary is replicating from the external primary. If the failed old primary comes back online, it is also replicating from the external server. To normalize the situation, either have auto_rejoin on or manually execute a rejoin. This will redirect the old primary to the current cluster primary.
Configuration parameters
auto_failover
- Type: enum
- Mandatory: No
- Dynamic: Yes
- Values:
true,on,yes,1,false,off,no,0,safe - Default:
false
Enable automatic primary failover. true, on, yes and 1 enable normal
failover. false, off, no and 0 disable the feature. safe enables
[safe failover]((#failover-safe).
When automatic failover is enabled, traditional MariaDB Primary-Replica clusters
will automatically elect a new primary if the old primary goes down and stays down
a number of iterations given in failcount. Failover will not take place when
MaxScale is configured as a passive instance. For details on how MaxScale
behaves in passive mode, see the documentation on failover_timeout below.
The monitor user must have the SUPER and RELOAD privileges for failover to work.
auto_rejoin
Enable automatic joining of server to the cluster. This parameter expects a boolean value and the default value is false.
When enabled, the monitor will attempt to direct standalone servers and servers replicating from a relay primary to the main cluster primary server, enforcing a 1-primary-N-replicas configuration.
For example, consider the following event series.
- Replica A goes down
- Primary goes down and a failover is performed, promoting Replica B
- Replica A comes back
Replica A is still trying to replicate from the downed primary, since it wasn't
online during failover. If auto_rejoin is on, Replica A will quickly be
redirected to Replica B, the current primary.
switchover_on_low_disk_space
This feature is disabled by default. If enabled, the monitor will attempt to
switchover a primary server low on disk space with a replica. The switch is only
done if a replica without disk space issues is found. If
maintenance_on_low_disk_space is also enabled, the old primary (now a replica)
will be put to maintenance during the next monitor iteration.
For this parameter to have any effect, disk_space_threshold must be specified
for the server
or the monitor.
Also, disk_space_check_interval
must be defined for the monitor.
switchover_on_low_disk_space=true
enforce_simple_topology
This setting tells the monitor to assume that the servers should be arranged in a
1-primary-N-replicas topology and the monitor should try to keep it that way. If
enforce_simple_topology is enabled, the settings assume_unique_hostnames,
auto_failover and auto_rejoin are also activated regardless of their individual
settings.
By default, mariadbmon will not rejoin servers with more than one replication
stream configured into the cluster. Starting with MaxScale 6.2.0, when
enforce_simple_topology is enabled, all servers will be rejoined into the
cluster and any extra replication sources will be removed. This is done to make
automated failover with multi-source external replication possible.
This setting also allows the monitor to perform a failover to a cluster where the primary server has not been seen [Running]. This is usually the case when the primary goes down before MaxScale is started. When using this feature, the monitor will guess the GTID domain id of the primary from the replicas. For reliable results, the GTID:s of the cluster should be simple.
enforce_simple_topology=true
replication_user and replication_password
The username and password of the replication user. These are given as the values
for MASTER_USER and MASTER_PASSWORD whenever a CHANGE MASTER TO command is
executed.
Both replication_user and replication_password parameters must be defined if
a custom replication user is used. If neither of the parameters is defined, the
CHANGE MASTER TO-command will use the monitor credentials for the replication
user.
The credentials used for replication must have the REPLICATION SLAVE
privilege.
replication_password uses the same encryption scheme as other password
parameters. If password encryption is in use, replication_password must be
encrypted with the same key to avoid erroneous decryption.
replication_master_ssl
Type: bool Default: off
If set to ON, any CHANGE MASTER TO-command generated will set MASTER_SSL=1 to enable
encryption for the replication stream. This setting should only be enabled if the backend
servers are configured for ssl. This typically means setting ssl_ca, ssl_cert and
ssl_key in the server configuration file. Additionally, credentials for the replication
user should require an encrypted connection (e.g. ALTER USER repl@'%' REQUIRE SSL;).
If the setting is left OFF, MASTER_SSL is not set at all, which will preserve existing
settings when redirecting a replica connection.
replication_custom_options
Type: string
A custom string added to "CHANGE MASTER TO"-commands sent by the monitor whenever setting up replication (e.g. during switchover). Useful for defining ssl certificates or other specialized replication options. MaxScale does not check the contents of the string, so care should be taken to ensure that only valid options are set and that the contents do not interfere with the options MaxScale sets on its own (e.g. MASTER_HOST). This setting can also be configured for an individual server. If configured for both the monitor and a server, the server setting takes priority.
replication_custom_options=MASTER_SSL_CERT = '/tmp/certs/client-cert.pem',
MASTER_SSL_KEY = '/tmp/certs/client-key.pem',
MASTER_SSL_CA = '/tmp/certs/ca.pem',
MASTER_SSL_VERIFY_SERVER_CERT=0
failover_timeout and switchover_timeout
Time limit for failover and switchover operations. The default
values are 90 seconds for both. switchover_timeout is also used as the time
limit for a rejoin operation. Rejoin should rarely time out, since it is a
faster operation than switchover.
The timeouts are specified as documented here. If no explicit unit is provided, the value is interpreted as seconds in MaxScale 2.4. In subsequent versions a value without a unit may be rejected. Note that since the granularity of the timeouts is seconds, a timeout specified in milliseconds will be rejected, even if the duration is longer than a second.
If no successful failover/switchover takes place within the configured time period, a message is logged and automatic failover is disabled. This prevents further automatic modifications to the misbehaving cluster.
verify_master_failure and master_failure_timeout
Enable additional primary failure verification for automatic failover.
verify_master_failure is a boolean value (default: true) which enables this
feature and master_failure_timeout defines the timeout (default: 10 seconds).
The primary failure timeout is specified as documented here. If no explicit unit is provided, the value is interpreted as seconds in MaxScale 2.4. In subsequent versions a value without a unit may be rejected. Note that since the granularity of the timeout is seconds, a timeout specified in milliseconds will be rejected, even if the duration is longer than a second.
Failure verification is performed by checking whether the replica servers are
still connected to the primary and receiving events. An event is either a change
in the Gtid_IO_Pos-field of the SHOW SLAVE STATUS output or a heartbeat
event. Effectively, if a replica has received an event within
master_failure_timeout duration, the primary is not considered down when
deciding whether to failover, even if MaxScale cannot connect to the primary.
master_failure_timeout should be longer than the Slave_heartbeat_period of
the replica connection to be effective.
If every replica loses its connection to the primary (Slave_IO_Running is not "Yes"), primary failure is considered verified regardless of timeout. This allows faster failover when the primary properly disconnects.
For automatic failover to activate, the failcount requirement must also be
met.
servers_no_promotion
This is a comma-separated list of server names that will not be chosen for primary promotion during a failover or autoselected for switchover. This does not affect switchover if the user selects the server to promote. Using this setting can disrupt new primary selection for failover such that an non-optimal server is chosen. At worst, this will cause replication to break. Alternatively, failover may fail if all valid promotion candidates are in the exclusion list.
servers_no_promotion=backup_dc_server1,backup_dc_server2
promotion_sql_file and demotion_sql_file
These optional settings are paths to text files with SQL statements in them. During promotion or demotion, the contents are read line-by-line and executed on the backend. Use these settings to execute custom statements on the servers to complement the built-in operations.
Empty lines or lines starting with '#' are ignored. Any results returned by the statements are ignored. All statements must succeed for the failover, switchover or rejoin to continue. The monitor user may require additional privileges and grants for the custom commands to succeed.
When promoting a replica to primary during switchover or failover, the
promotion_sql_file is read and executed on the new primary server after its
read-only flag is disabled. The commands are ran before starting replication
from an external primary if any.
demotion_sql_file is ran on an old primary during demotion to replica, before the
old primary starts replicating from the new primary. The file is also ran before
rejoining a standalone server to the cluster, as the standalone server is
typically a former primary server. When redirecting a replica replicating from a
wrong primary, the sql-file is not executed.
Since the queries in the files are ran during operations which modify
replication topology, care is required. If promotion_sql_file contains data
modification (DML) queries, the new primary server may not be able to
successfully replicate from an external primary. demotion_sql_file should never
contain DML queries, as these may not replicate to the replica servers before
replica threads are stopped, breaking replication.
promotion_sql_file=/home/root/scripts/promotion.sql demotion_sql_file=/home/root/scripts/demotion.sql
handle_events
This setting is on by default. If enabled, the monitor continuously queries the servers for enabled scheduled events and uses this information when performing cluster operations, enabling and disabling events as appropriate.
When a server is being demoted, any events with "ENABLED" status are set to "SLAVESIDE_DISABLED". When a server is being promoted to primary, events that are either "SLAVESIDE_DISABLED" or "DISABLED" are set to "ENABLED" if the same event was also enabled on the old primary server last time it was successfully queried. Events are considered identical if they have the same schema and name. When a standalone server is rejoined to the cluster, its events are also disabled since it is now a replica.
The monitor does not check whether the same events were disabled and enabled during a switchover or failover/rejoin. All events that meet the criteria above are altered.
The monitor does not enable or disable the event scheduler itself. For the events to run on the new primary server, the scheduler should be enabled by the admin. Enabling it in the server configuration file is recommended.
Events running at high frequency may cause replication to break in a failover scenario. If an old primary which was failed over restarts, its event scheduler will be on if set in the server configuration file. Its events will also remember their "ENABLED"-status and run when scheduled. This may happen before the monitor rejoins the server and disables the events. This should only be an issue for events running more often than the monitor interval or events that run immediately after the server has restarted.
Cooperative monitoring
As of MaxScale 2.5, MariaDB-Monitor supports cooperative monitoring. This means that multiple monitors (typically in different MaxScale instances) can monitor the same backend server cluster and only one will be the primary monitor. Only the primary monitor may perform switchover, failover or rejoin operations. The primary also decides which server is the primary. Cooperative monitoring is enabled with the cooperative_monitoring_locks-setting. Even with this setting, only one monitor per server per MaxScale is allowed. This limitation can be circumvented by defining multiple copies of a server in the configuration file.
Cooperative monitoring uses server locks for coordinating between monitors. When cooperating, the monitor regularly checks the status of a lock named maxscale_mariadbmonitor on every server and acquires it if free. If the monitor acquires a majority of locks, it is the primary. If a monitor cannot claim majority locks, it is a secondary monitor.
The primary monitor of a cluster also acquires the lock maxscale_mariadbmonitor_master on the primary server. Secondary monitors check which server this lock is taken on and only accept that server as the primary. This arrangement is required so that multiple monitors can agree on which server is the primary regardless of replication topology. If a secondary monitor does not see the primary-lock taken, then it won't mark any server as [Master], causing writes to fail.
The lock-setting defines how many locks are required for primary status. Setting
cooperative_monitoring_locks=majority_of_all means that the primary monitor
needs n_servers/2 + 1 (rounded down) locks. For example, a cluster of three
servers needs two locks for majority, a cluster of four needs three, and a
cluster of five needs three.
This scheme is resistant against split-brain situations in the sense
that multiple monitors cannot be primary simultaneously. However, a split may
cause both monitors to consider themselves secondary, in which case a primary
server won't be detected.
Even without a network split, cooperative_monitoring_locks=majority_of_all
will lead to neither monitor claiming lock majority once too many servers go
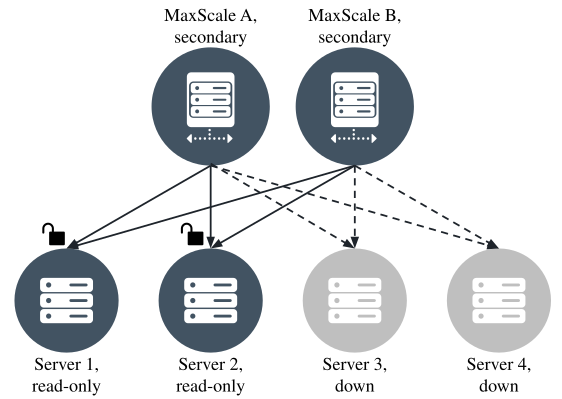
down. This scenario is depicted in the image below. Only two out of four servers
are running when three are needed for majority. Although both MaxScales see both
running servers, neither is certain they have majority and the cluster stays in
read-only mode. If the primary server is down, no failover is performed either.
Setting cooperative_monitoring_locks=majority_of_running changes the way
n_servers is calculated. Instead of using the total number of servers, only
servers currently [Running] are considered. This scheme adapts to multiple
servers going down, ensuring that claiming lock majority is always possible.
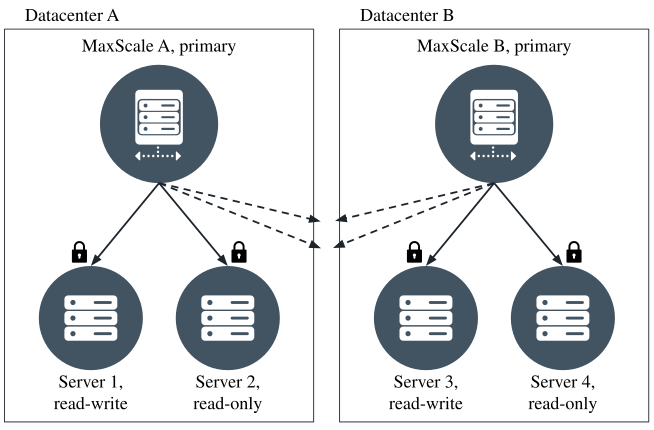
However, it can lead to multiple monitors claiming primary status in a
split-brain situation. As an example, consider a cluster with servers 1 to 4
with MaxScales A and B, as in the image below. MaxScale A can connect to
servers 1 and 2 (and claim their locks) but not to servers 3 and 4 due to
a network split. MaxScale A thus assumes servers 3 and 4 are down. MaxScale B
does the opposite, claiming servers 3 and 4 and assuming 1 and 2 are down.
Both MaxScales claim two locks out of two available and assume that they have
lock majority. Both MaxScales may then promote their own primaries and route
writes to different servers.
The recommended strategy depends on which failure scenario is more likely and/or more destructive. If it's unlikely that multiple servers are ever down simultaneously, then majority_of_all is likely the safer choice. On the other hand, if split-brain is unlikely but multiple servers may be down simultaneously, then majority_of_running would keep the cluster operational.
To check if a monitor is primary, fetch monitor diagnostics with maxctrl show
monitors or the REST API. The boolean field primary indicates whether the
monitor has lock majority on the cluster. If cooperative monitoring is disabled,
the field value is null. Lock information for individual servers is listed in
the server-specific field lock_held. Again, null indicates that locks are
not in use or the lock status is unknown.
If a MaxScale instance tries to acquire the locks but fails to get majority (perhaps another MaxScale was acquiring locks simultaneously) it will release any acquired locks and try again after a random number of monitor ticks. This prevents multiple MaxScales from fighting over the locks continuously as one MaxScale will eventually wait less time than the others. Conflict probability can be further decreased by configuring each monitor with a different monitor_interval.
The flowchart below illustrates the lock handling logic.

Releasing locks
Monitor cooperation depends on the server locks. The locks are connection-specific. The owning connection can manually release a lock, allowing another connection to claim it. Also, if the owning connection closes, the MariaDB Server process releases the lock. How quickly a lost connection is detected affects how quickly the primary monitor status moves from one monitor and MaxScale to another.
If the primary MaxScale or its monitor is stopped normally, the monitor connections are properly closed, releasing the locks. This allows the secondary MaxScale to quickly claim the locks. However, if the primary simply vanishes (broken network), the connection may just look idle. In this case, the MariaDB Server may take a long time before it considers the monitor connection lost. This time ultimately depends on TCP keepalive settings on the machines running MariaDB Server.
On MariaDB Server 10.3.3 and later, the TCP keepalive settings can be configured for just the server process. See Server System Variables for information on settings tcp_keepalive_interval, tcp_keepalive_probes and tcp_keepalive_time. These settings can also be set on the operating system level, as described here.
As of MaxScale 6.4.16, 22.08.13, 23.02.10, 23.08.6 and 24.02.2, configuring TCP keepalive is no longer necessary as monitor sets the session wait_timeout variable when acquiring a lock. This causes the MariaDB Server to close the monitor connection if the connection appears idle for too long. The value of wait_timeout used depends on the monitor interval and connection timeout settings, and is logged at MaxScale startup.
A monitor can also be ordered to manually release its locks via the module command release-locks. This is useful for manually changing the primary monitor. After running the release-command, the monitor will not attempt to reacquire the locks for one minute, even if it wasn't the primary monitor to begin with. This command can cause the cluster to become temporarily unusable by MaxScale. Only use it when there is another monitor ready to claim the locks.
maxctrl call command mariadbmon release-locks MyMonitor1
Primary server write test
Some backend failures are not observable just by connecting to the server and running standard monitor queries. A server may be connectable and respond to queries sent by the monitor, but its disk could be full or malfunctioning or the storage engine could be locked in some way. Normally, MariaDB Monitor would consider such a server to be in good health, even if in reality the server could not perform any writes.
To detect such errors, MariaDB Monitor can be configured to perform a regular write test if the gtid_binlog_pos of the primary server is not advancing otherwise. Testing that writes are going through and are being saved to the binary log increases the chance of detecting storage failures. The monitor can also be configured to perform a failover if the primary server fails the write test. Even this test may miss storage issues, as the monitor write test performs a small insert that may go through even when a large write done by a real application does not.
See the following configuration parameters for more information on how to configure this feature.
write_test_interval
- Type: duration
- Dynamic: Yes
- Default: 0s
If enabled (value > 0s), the monitor will perform a write test on the primary server if its gtid_binlog_pos has not changed within the configured interval. This test inserts one row to the table configured in write_test_table. If the insert fails or does not complete within backend_read_timeout, the server fails the write test. What happens after that depends on write_test_fail_action.
write_test_interval=20s
write_test_table
- Type: string
- Dynamic: Yes
- Default:
mxs.maxscale_write_test
The write test target table. The table name should be fully qualified i.e. include the database name. If the table does not exist or does not contain expected columns, the monitor (re)creates it. The table is created with a query like
create or replace table mxs.maxscale_write_test (id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY NOT NULL, `date` TIMESTAMP DEFAULT CURRENT_TIMESTAMP, `gtid` TEXT NULL);
The database must be created manually. The monitor user requires privileges to create, drop, read and manipulate the table:
GRANT SELECT, INSERT, DELETE, CREATE, DROP ON `mxs`.* TO 'maxscale'@'maxscalehost';
write_test_table=mxs.my_write_test_table
write_test_fail_action
- Type: enum
- Default:
log - Values:
log,failover - Dynamic: Yes
Which action to take if primary server fails the write test. log means that
MaxScale will simply log the failure but perform no other action. This is mainly
useful for testing the feature.
If set to failover, the monitor will perform a failover if the primary server
fails the write test failcount consecutive times. That is,
the first write test is performed after write_test_interval has passed without
writes. If the test fails, the monitor will repeat the test during the next
monitor tick. After failcount monitor ticks with failed write tests, failover
begins. After failover, the former primary server is set into maintenance mode.
Manual intervention is required to take the server into use again.
Backup operations
Backup operations manipulate the contents of a MariaDB Server, saving it or overwriting it. MariaDB-Monitor supports three backup operations:
- rebuild-server: Replace the contents of a database server with the contents of another.
- create-backup: Copy the contents of a database server to a storage location.
- restore-from-backup: Overwrite the contents of a database server with a backup.
These operations do not modify server config files, only files in the data directory (typically /var/lib/mysql) are affected.
All of these operations are monitor commands and best launched with MaxCtrl.
The operations are asynchronous, which means MaxCtrl won't wait for the
operation to complete and instead immediately returns "OK". To see the current
status of an operation, either check MaxScale log or use the
fetch-cmd-result-command
(e.g. maxctrl call command mariadbmon fetch-cmd-result MyMonitor).
To perform backup operations, MaxScale requires ssh-access on all affected machines. The ssh_user and ssh_keyfile-settings define the SSH credentials MaxScale uses to access the servers. MaxScale must be able to run commands with sudo on both the source and target servers. See settings and sudoers.d configuration below for more information.
The following tools need to be installed on the backends:
- Mariabackup. Backs up and restores MariaDB Server contents. Installed e.g.
with
yum install MariaDB-backup. See Mariabackup documentation for more information. - pigz. Compresses and decompresses the backup stream. Installed e.g. with
yum install pigz. - socat. Streams data from one machine to another. Is likely already
installed. If not, can be installed e.g. with
yum install socat.
Mariabackup needs server credentials to log in and authenticate to the MariaDB Server being copied from. For this, MaxScale uses the monitor user. The monitor user may thus require additional privileges. See Mariabackup documentation for more details.
Rebuild server
The rebuild server-operation replaces the contents of a database server with the contents of another server. The source server is effectively cloned and all data on the target server is lost. This is useful when a replica server has diverged from the primary server, or when adding a new server to the cluster. MaxScale performs this operation by running Mariabackup on both the source and target servers.
When launched, the rebuild operation proceeds as below. If any step fails, the operation is stopped and the target server will be left in an unspecified state.
- Log in to both servers with ssh and check that the tools listed above are
present (e.g.
mariabackup -vshould succeed). - Check that the port used for transferring the backup is free on the source server. If not, kill the process holding it. This requires running lsof and kill.
- Test the connection by streaming a short message from the source host to the target.
- Launch Mariabackup on the source machine, compress the stream and listen
for an incoming connection. This is performed with a command like
mariabackup --backup --safe-slave-backup --stream=xbstream --parallel=1 | pigz -c | socat - TCP-LISTEN:<port>. - Ask the target server what its data directory is (
select @@datadir;). Stop MariaDB Server on the target machine and delete all contents of the data directory. - On the target machine, connect to the source machine, read the backup stream,
decompress it and write to the data directory. This is performed with a command
like
socat -u TCP:<host>:<port> STDOUT | pigz -dc | mbstream -x. This step can take a long time if there is much data to transfer. - Check that the data directory on the target machine is not empty, i.e. that the transfer at least appears to have succeeded.
- Prepare the backup on the target server with a command like
mariabackup --use-memory=1G --prepare. This step can also take some time if the source server performed writes during data transfer. - On the target server, change ownership of datadir contents to the mysql-user and start MariaDB-server.
- Read gtid from the data directory. Have the target server start replicating from the primary if it is not one already.
The rebuild-operation is a monitor module command and takes four arguments:
- Monitor name, e.g. MyMonitor.
- Target server name, e.g. MyTargetServer.
- Source server name, e.g. MySourceServer. This parameter is optional.
If not specified, the monitor prefers to autoselect an up-to-date replica
server to avoid increasing load on the primary server. Due to the
--safe-slave-backup-option, the replica will stop replicating until the backup data has been transferred. - Data directory on target server. This parameter is optional. If not specified, the monitor will ask the target server. If target server is not running, monitor will assume /var/lib/mysql. Thus, this only needs to be defined with non-standard directory setups.
The following example rebuilds MyTargetServer with contents of MySourceServer.
maxctrl call command mariadbmon async-rebuild-server MyMonitor MyTargetServer MySourceServer
The following example uses a custom data directory on the target.
maxctrl call command mariadbmon async-rebuild-server MyMonitor MyTargetServer MySourceServer /my_datadir
The operation does not launch if the target server is already replicating or if the source server is not a primary or replica.
Steps 6 and 8 can take a long time depending on the size of the database and if writes are ongoing. During these steps, the monitor will continue monitoring the cluster normally. After each monitor tick the monitor checks if the rebuild-operation can proceed. No other monitor operations, either manual or automatic, can run until the rebuild completes.
Create backup
The create backup-operation copies the contents of a database server to the backup storage. The source server is not modified but may slow down during backup creation. MaxScale performs this operation by running Mariabackup on both the source and storage servers. The storage location is defined by the backup_storage_address and backup_storage_path settings. Normal ssh-settings are used to access the storage server. The backup storage machine does not need to have a MariaDB Server installed.
Backup creation runs somewhat similar to rebuild-server. The main difference is that the backup data is simply saved to a directory and not prepared or used to start a MariaDB Server. If any step fails, the operation is stopped and the backup storage directory will be left in an unspecified state.
- Init. See rebuild-server.
- Check listen port on backup storage machine. See rebuild-server.
- Check that the backup storage main directory exists. Check that it does not contain a backup with the same name as the one being created. Create the final backup directory.
- Test the connection by streaming a short message from the source host to the backup storage.
- Serve backup on source. Similar to rebuild-server step 4.
- Transfer backup directly to the final storage directory. Similar to rebuild-server step 5.
- Check that the copied backup data looks ok.
Backup creation is a monitor module command and takes three arguments: the monitor name, source server name and backup name. Backup name defines the subdirectory where the backup is saved and should be a valid directory name. The command
maxctrl call command mariadbmon async-create-backup MyMonitor MySourceServer wednesday_161122
would save the backup of MySourceServer to
<backup_storage_path>/wednesday_161122 on the host defined in
backup_storage_address. ssh_user needs to have read and write access
to the main storage directory. The source server must be a primary or replica.
Similar to rebuild-server, the monitor will continue monitoring the servers while the backup is transferred.
Restore from backup
The restore-operation is the reverse of create-backup. It overwrites the contents of an existing MariaDB Server with a backup from the backup storage. The backup is not removed and can be used again. MaxScale performs this operation by transferring the backup contents as a tar archive and overwriting the target server data directory. The backup storage is defined in monitor settings similar to create-backup.
The restore-operation runs somewhat similar to rebuild-server. The main difference is that the backup data is copied with tar instead of Mariabackup. If any step fails, the operation is stopped and the target server will be left in an unspecified state.
- Init. See rebuild-server.
- Check listen port on target machine. See rebuild-server.
- Check that the backup storage main directory exists and that it contains a backup with the name requested.
- Test the connection by streaming a short message from the backup storage to the target machine.
- On the backup storage machine, compress the backup with tar and serve it
with socat, listening for an incoming connection. This is performed with
a command like
tar -zc -C <backup_dir> . | socat - TCP-LISTEN:<port>. - Ask the target server what its data directory is (
select @@datadir;). Stop MariaDB Server on the target machine and delete all contents of the data directory. - On the target machine, connect to the source machine, read the backup stream,
decompress it and write to the data directory. This is performed with a command
like
socat -u TCP:<host>:<port> STDOUT | sudo tar -xz -C /var/lib/mysql/. This step can take a long time if there is much data to transfer. - From here on, the operation proceeds as from rebuild-server step 7.
Server restoration is a monitor module command and takes four arguments.
- Monitor name, e.g. MyMonitor.
- Target server name, e.g. MyNewServer.
- Backup name. This parameter defines the subdirectory where the backup is read from and should be an existing directory on the backup storage host.
- Data directory on target server. This parameter is optional. If not specified, the monitor will ask the target server. If target server is not running, monitor will assume /var/lib/mysql. Thus, this only needs to be defined with non-standard directory setups.
The command
maxctrl call command mariadbmon async-restore-from-backup MyMonitor MyTargetServer wednesday_161122
would erase the contents of MyTargetServer and replace them with the backup
contained in
<backup_storage_path>/wednesday_161122 on the host defined in
backup_storage_address. ssh_user needs to have read access
to the main storage directory and the backup. The target server must not be
a primary or replica.
The following example uses a custom data directory on the target.
maxctrl call command mariadbmon async-restore-from-backup MyMonitor MyTargetServer wednesday_161122 /my_datadir
Similar to rebuild-server, the monitor will continue monitoring the servers while the backup is transferred and prepared.
Settings
ssh_user
String. Ssh username. Used when logging in to backend servers to run commands.
ssh_keyfile
Path to file with an ssh private key. Used when logging in to backend servers to run commands.
ssh_check_host_key
Boolean, default: true. When logging in to backends, require that the server is already listed in the known_hosts-file of the user running MaxScale.
ssh_timeout
Time, default: 10s. The rebuild operation consists of multiple ssh commands. Most of the commands are assumed to complete quickly. If these commands take more than ssh_timeout to complete, the operation fails. Adjust this setting if rebuild fails due to ssh commands timing out. This setting does not affect steps 5 and 6, as these are assumed to take significant time.
ssh_port
Numeric, default: 22. SSH port. Used for running remote commands on servers.
rebuild_port
Numeric, default: 4444. The port which the source server listens on for a connection. The port must not be blocked by a firewall or listened on by any other program. If another process is listening on the port when rebuild is starting, MaxScale will attempt to kill the process.
mariabackup_use_memory
String, default: "1G". Given as is to
mariabackup --prepare --use-memory=<mariabackup_use_memory>. If set to empty,
no --use-memory is set and Mariabackup will use its internal default. See
here for more
information.
mariabackup_use_memory=2G
mariabackup_parallel
Numeric, default: 1. Given as is tomariabackup --backup --parallel=<val>.
Defines the number of threads used for parallel data file transfer. See
here for more
information.
mariabackup_parallel=2
backup_storage_address
String. Address of the backup storage. Does not need to have MariaDB Server running or be monitored by the monitor. Connected to with ssh. Must have enough disk space to store all backups.
backup_storage_address=192.168.1.11
backup_storage_path
String. Path to main backup storage directory on backup storage host. ssh_user needs to have full access to this directory to save and read backups.
/home/maxscale_ssh_user/backup_storage
sudoers.d configuration
If giving MaxScale general sudo-access is out of the question, MaxScale must be
allowed to run the specific commands required by the backup operations. This can
be achieved by creating a file with the commands in the
/etc/sudoers.d-directory. In the example below, the user johnny is given the
power to run commands as root. The contents of the file may need to be tweaked
due to changes in install locations.
johnny ALL= NOPASSWD: /bin/systemctl stop mariadb johnny ALL= NOPASSWD: /bin/systemctl start mariadb johnny ALL= NOPASSWD: /usr/sbin/lsof johnny ALL= NOPASSWD: /bin/kill johnny ALL= NOPASSWD: /usr/bin/mariabackup johnny ALL= NOPASSWD: /bin/mbstream johnny ALL= NOPASSWD: /bin/rm -rf /var/lib/mysql/* johnny ALL= NOPASSWD: /bin/chown -R mysql\:mysql /var/lib/mysql johnny ALL= NOPASSWD: /bin/cat /var/lib/mysql/xtrabackup_binlog_info johnny ALL= NOPASSWD: /bin/tar -xz -C /var/lib/mysql/
ColumnStore commands
Since MaxScale version 22.08, MariaDB Monitor can run ColumnStore administrative commands against a ColumnStore cluster. The commands interact with the ColumnStore REST-API present in recent ColumnStore versions and have been tested with MariaDB-Server 10.6 running the ColumnStore plugin version 6.2. None of the commands affect monitor configuration or replication topology. MariaDB Monitor simply relays the commands to the backend cluster.
MariaDB Monitor can fetch cluster status, add and remove nodes, start and stop
the cluster, and set cluster read-only or readwrite. MaxScale only communicates
with the first server in the servers-list.
Most of the commands are asynchronous, i.e. they do not wait for the operation to complete on the ColumnStore backend before returning to the command prompt. MariaDB Monitor itself, however, runs the command in the background and does not perform normal monitoring until the operation completes or fails. After an operation has started the user should use fetch-cmd-result to check its status. The examples below show how to run the commands using MaxCtrl. If a command takes a timeout-parameter, the timeout can be given in seconds (s), minutes (m) or hours (h).
ColumnStore command settings are listed here. At least
cs_admin_api_key must be set.
Get status
Fetch cluster status. Returns the result as is. Status fetching has an automatic timeout of ten seconds.
maxctrl call command mariadbmon cs-get-status <monitor-name> maxctrl call command mariadbmon async-cs-get-status <monitor-name>
Examples:
maxctrl call command mariadbmon cs-get-status MyMonitor
{
"mcs1": {
"cluster_mode": "readwrite",
"dbrm_mode": "master",
<snip>
maxctrl call command mariadbmon async-cs-get-status MyMonitor
OK
maxctrl call command mariadbmon fetch-cmd-result MyMonitor
{
"mcs1": {
"cluster_mode": "readwrite",
"dbrm_mode": "master",
<snip>
Add or remove node
Add or remove a node to/from the ColumnStore cluster.
maxctrl call command mariadbmon async-cs-add-node <monitor-name> <node-host> <timeout> maxctrl call command mariadbmon async-cs-remove-node <monitor-name> <node-host> <timeout>
<node-host> is the hostname or IP of the node being added or removed.
Examples:
maxctrl call command mariadbmon async-cs-add-node MyMonitor mcs3 1m
OK
maxctrl call command mariadbmon fetch-cmd-result MyMonitor
{
"node_id": "mcs3",
"timestamp": "2022-05-05 08:07:51.518268"
}
maxctrl call command mariadbmon async-cs-remove-node MyMonitor mcs3 1m
OK
maxctrl call command mariadbmon fetch-cmd-result MyMonitor
{
"node_id": "mcs3",
"timestamp": "2022-05-05 10:46:46.506947"
}
Start and stop cluster
maxctrl call command mariadbmon async-cs-start-cluster <monitor-name> <timeout> maxctrl call command mariadbmon async-cs-stop-cluster <monitor-name> <timeout>
Examples:
maxctrl call command mariadbmon async-cs-start-cluster MyMonitor 1m
OK
maxctrl call command mariadbmon fetch-cmd-result MyMonitor
{
"timestamp": "2022-05-05 09:41:57.140732"
}
maxctrl call command mariadbmon async-cs-stop-cluster MyMonitor 1m
OK
maxctrl call command mariadbmon fetch-cmd-result MyMonitor
{
"mcs1": {
"timestamp": "2022-05-05 09:45:33.779837"
},
<snip>
Set read-only or readwrite
maxctrl call command mariadbmon async-cs-set-readonly <monitor-name> <timeout> maxctrl call command mariadbmon async-cs-set-readwrite <monitor-name> <timeout>
Examples:
maxctrl call command mariadbmon async-cs-set-readonly MyMonitor 30s
OK
maxctrl call command mariadbmon fetch-cmd-result MyMonitor
{
"cluster-mode": "readonly",
"timestamp": "2022-05-05 09:49:18.365444"
}
maxctrl call command mariadbmon async-cs-set-readwrite MyMonitor 30s
OK
maxctrl call command mariadbmon fetch-cmd-result MyMonitor
{
"cluster-mode": "readwrite",
"timestamp": "2022-05-05 09:50:30.718972"
}
Settings
cs_admin_port
Numeric, default: 8640. The REST-API port on the ColumnStore nodes. All nodes are assumed to listen on the same port.
cs_admin_port=8641
cs_admin_api_key
String. The API-key MaxScale sends to the ColumnStore nodes when making a REST-API request. Should match the value configured on the ColumnStore nodes.
cs_admin_api_key=somekey123
cs_admin_base_path
String, default: /cmapi/0.4.0. Base path sent with the REST-API request.
Other commands
fetch-cmd-result
Fetches the result of the last manual command. Requires monitor name as parameter. Most commands only return a generic success message or an error description. ColumnStore commands may return more data. Scheduling another command clears a stored result.
maxctrl call command mariadbmon fetch-cmd-result MariaDB-Monitor "switchover completed successfully."
cancel-cmd
Cancels the latest operation, whether manual or automatic, if possible. Requires monitor name as parameter. A scheduled manual command is simply canceled before it can run. If a command is already running, it stops as soon as possible. The cancel-cmd itself does not wait for a running operation to stop. Use fetch-cmd-result or check the log to see if the operation has truly completed. Canceling is most useful for stopping a stalled rebuild operation.
maxctrl call command mariadbmon cancel-cmd MariaDB-Monitor OK
Troubleshooting
Failover/switchover fails
See the Limitations and requirements-section.
Before performing failover or switchover, the monitor checks that prerequisites are fulfilled, printing any errors and warnings found. This should catch and explain most issues with failover or switchover not working. If the operations are attempted and still fail, then most likely one of the commands the monitor issued to a server failed or timed out. The log should explain which query failed.
A typical failure reason is that a command such as STOP SLAVE takes longer than the
backend_read_timeout of the monitor, causing the connection to break. As of 2.3, the
monitor will retry most such queries if the failure was caused by a timeout. The retrying
continues until the total time for a failover or switchover has been spent. If the log
shows warnings or errors about commands timing out, increasing the backend timeout
settings of the monitor should help. Other settings to look at are query_retries and
query_retry_timeout. These are general MaxScale settings described in the
Configuration guide. Setting
query_retries to 2 is a reasonable first try.
If switchover causes the old primary (now replica) to fail replication, then most
likely a user or perhaps a scheduled event performed a write while monitor
had set read_only=1. This is possible if the user performing the write has
"SUPER" or "READ_ONLY ADMIN" privileges. The switchover-operation tries to kick
out SUPER-users but this is not certain to succeed. Remove these privileges
from any users that regularly do writes to prevent them from interfering with
switchover.
The server configuration files should have log-slave-updates=1 to ensure that
a newly promoted primary has binary logs of previous events. This allows the new
primary to replicate past events to any lagging replicas.
To print out all queries sent to the servers, start MaxScale with
--debug=enable-statement-logging. This setting prints all queries sent to the
backends by monitors and authenticators. The printed queries may include
usernames and passwords.
Replica detection shows external primaries
If a replica is shown in maxctrl as "Slave of External Server" instead of
"Slave", the reason is likely that the "Master_Host"-setting of the replication connection
does not match the MaxScale server definition. As of 2.3.2, the MariaDB Monitor by default
assumes that the replica connections (as shown by SHOW ALL SLAVES STATUS) use the exact
same "Master_Host" as used the MaxScale configuration file server definitions. This is
controlled by the setting assume_unique_hostnames.
Using the MariaDB Monitor With Binlogrouter
Since MaxScale 2.2 it's possible to detect a replication setup which includes Binlog Server: the required action is to add the binlog server to the list of servers only if master_id identity is set.
